🌟 Diving into Contextual Retrieval with LangChain 🌟
Welcome to an exciting journey into Contextual Retrieval! This blog post will guide you through implementing Anthropic’s Contextual Retrieval using LangChain in a simple, colorful, and beginner-friendly way. Let’s make complex retrieval systems easy to understand! 🚀
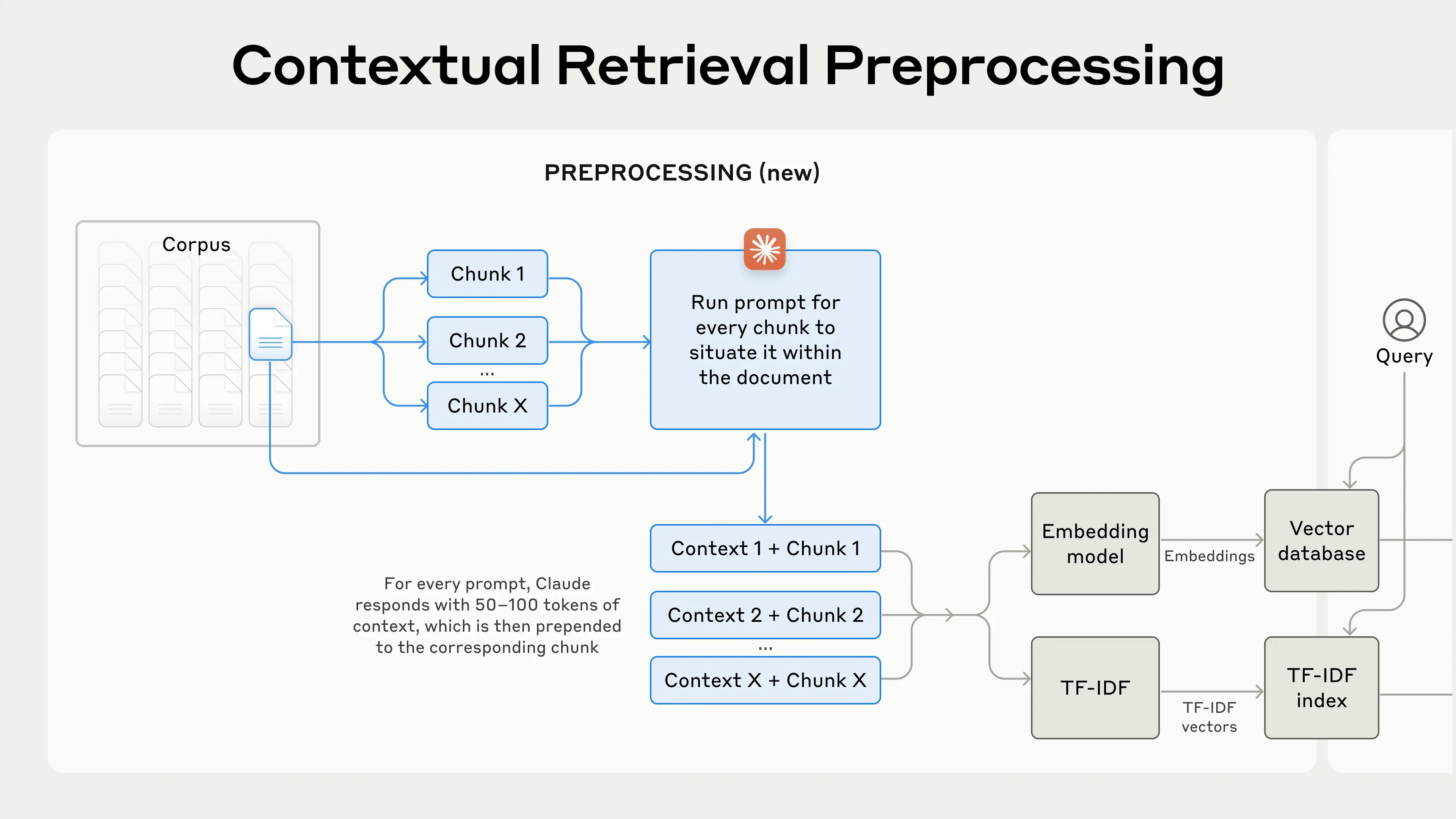
🎯 What is Contextual Retrieval?
Traditional Retrieval-Augmented Generation (RAG) systems can miss the mark because they don’t provide enough context for document chunks. Contextual Retrieval solves this by adding a short explanation to each chunk before embedding it, making searches smarter and more accurate. Let’s see how it works with code!
1️⃣ Setting Up the Environment
import logging
import os
logging.disable(level=logging.INFO)
os.environ["TOKENIZERS_PARALLELISM"] = "true"
os.environ["AZURE_OPENAI_API_KEY"] = ""
os.environ["AZURE_OPENAI_ENDPOINT"] = ""
os.environ["COHERE_API_KEY"] = ""
What’s happening here? We import basic libraries, disable unnecessary logging, and set environment variables for Azure OpenAI and Cohere APIs. This prepares our system to use these services.
2️⃣ Installing Required Libraries
!pip install -q langchain langchain-openai langchain-community faiss-cpu rank_bm25 langchain-cohere
Why this? This command installs LangChain and its dependencies, including tools for embeddings (FAISS), ranking (BM25), and reranking (Cohere). The -q keeps the output quiet.
3️⃣ Importing LangChain Tools
from langchain.document_loaders import TextLoader
from langchain.prompts import PromptTemplate
from langchain.retrievers import BM25Retriever
from langchain.vectorstores import FAISS
from langchain_cohere import CohereRerank
from langchain_openai import AzureChatOpenAI, AzureOpenAIEmbeddings
What’s this doing? We import LangChain modules for loading documents, creating prompts, retrieving data (BM25 and FAISS), reranking results, and connecting to Azure’s LLM and embedding models.
4️⃣ Downloading the Dataset
!wget 'https://raw.githubusercontent.com/run-llama/llama_index/main/docs/docs/examples/data/paul_graham/paul_graham_essay.txt' -O './paul_graham_essay.txt'
What’s this? We download a sample dataset (Paul Graham’s essay) from a public URL and save it as a text file for processing.
5️⃣ Setting Up the LLM and Embeddings
llm = AzureChatOpenAI(
deployment_name="gpt-4-32k-0613",
openai_api_version="2023-08-01-preview",
temperature=0.0,
)
embeddings = AzureOpenAIEmbeddings(
deployment="text-embedding-ada-002",
api_version="2023-08-01-preview",
)
What’s happening? We initialize Azure’s GPT-4 model for text generation (with zero temperature for precise outputs) and set up the embedding model to convert text into vectors for similarity search.
6️⃣ Loading the Data
loader = TextLoader("./paul_graham_essay.txt")
documents = loader.load()
WHOLE_DOCUMENT = documents[0].page_content
Why this? We load the essay text file into a LangChain document object and store its content in WHOLE_DOCUMENT for further processing.
7️⃣ Creating Prompts for Contextual Chunks
prompt_document = PromptTemplate(
input_variables=["WHOLE_DOCUMENT"], template="{WHOLE_DOCUMENT}"
)
prompt_chunk = PromptTemplate(
input_variables=["CHUNK_CONTENT"],
template="Here is the chunk we want to situate within the whole document\n\n{CHUNK_CONTENT}\n\n"
"Please give a short succinct context to situate this chunk within the overall document for "
"the purposes of improving search retrieval of the chunk. Answer only with the succinct context and nothing else.",
)
What’s this for? We define two prompt templates: one to pass the entire document and another to generate a concise context for each chunk, which will improve retrieval accuracy.
8️⃣ Splitting Text into Chunks
from langchain.text_splitter import RecursiveCharacterTextSplitter
def split_text(texts):
text_splitter = RecursiveCharacterTextSplitter(chunk_overlap=200)
doc_chunks = text_splitter.create_documents(texts)
for i, doc in enumerate(doc_chunks):
doc.metadata = {"doc_id": f"doc_{i}"}
return doc_chunks
What’s this doing? This function splits the document into smaller chunks with a 200-character overlap to ensure continuity. Each chunk gets a unique ID in its metadata.
9️⃣ Creating Retrievers
def create_embedding_retriever(documents_):
vector_store = FAISS.from_documents(documents_, embedding=embeddings)
return vector_store.as_retriever(search_kwargs={"k": 4})
def create_bm25_retriever(documents_):
retriever = BM25Retriever.from_documents(documents_, language="english")
return retriever
What’s happening? We create two retrievers: one using FAISS for vector-based similarity search (returns top 4 results) and another using BM25 for keyword-based ranking.
🔟 Combining Retrievers with Reranking
class EmbeddingBM25RerankerRetriever:
def __init__(self, vector_retriever, bm25_retriever, reranker):
self.vector_retriever = vector_retriever
self.bm25_retriever = bm25_retriever
self.reranker = reranker
def invoke(self, query):
vector_docs = self.vector_retriever.invoke(query)
bm25_docs = self.bm25_retriever.invoke(query)
combined_docs = vector_docs + [doc for doc in bm25_docs if doc not in vector_docs]
reranked_docs = self.reranker.compress_documents(combined_docs, query)
return reranked_docs
Why this? This class combines vector and BM25 retrievers, merges their results, and uses Cohere’s reranker to prioritize the most relevant documents for a given query.
1️⃣1️⃣ Adding Context to Chunks
def create_contextual_chunks(chunks_):
contextual_documents = []
for chunk in tqdm.tqdm(chunks_):
context = prompt_document.format(WHOLE_DOCUMENT=WHOLE_DOCUMENT)
chunk_context = prompt_chunk.format(CHUNK_CONTENT=chunk)
llm_response = llm.invoke(context + chunk_context).content
page_content = f"""Text: {chunk.page_content}\n\n\nContext: {llm_response}"""
doc = Document(page_content=page_content, metadata=chunk.metadata)
contextual_documents.append(doc)
return contextual_documents
What’s this? This function adds a contextual explanation to each chunk using the LLM and prompt templates, creating new documents that include both the chunk text and its context.
1️⃣2️⃣ Generating Question-Context Pairs
def generate_question_context_pairs(documents, llm, num_questions_per_chunk=2):
doc_dict = {doc.metadata["doc_id"]: doc.page_content for doc in documents}
queries = {}
relevant_docs = {}
for doc_id, text in tqdm(doc_dict.items()):
query = DEFAULT_QA_GENERATE_PROMPT_TMPL.format(context_str=text, num_questions_per_chunk=num_questions_per_chunk)
response = llm.invoke(query).content
questions = [re.sub(r"^\d+[\).\s]", "", q).strip() for q in re.split(r"\n+", response.strip()) if q.strip()]
questions = questions[:num_questions_per_chunk]
for question in questions:
question_id = str(uuid.uuid4())
queries[question_id] = question
relevant_docs[question_id] = [doc_id]
return QuestionContextEvalDataset(queries=queries, corpus=doc_dict, relevant_docs=relevant_docs)
What’s this for? This generates questions for each chunk (2 per chunk) using the LLM and creates a dataset mapping questions to their relevant document IDs for evaluation.
1️⃣3️⃣ Evaluating Retrievers
def evaluate(retriever, dataset):
mrr_result = []
hit_rate_result = []
ndcg_result = []
for i in tqdm(range(len(dataset.queries))):
context = retriever.invoke(extract_queries(dataset)[i])
expected_ids = dataset.relevant_docs[list(dataset.queries.keys())[i]]
retrieved_ids = extract_doc_ids(context)
mrr = compute_mrr(expected_ids=expected_ids, retrieved_ids=retrieved_ids)
hit_rate = compute_hit_rate(expected_ids=expected_ids, retrieved_ids=retrieved_ids)
ndcg = compute_ndcg(expected_ids=expected_ids, retrieved_ids=retrieved_ids)
mrr_result.append(mrr)
hit_rate_result.append(hit_rate)
ndcg_result.append(ndcg)
results_df = pd.DataFrame(np.mean([mrr_result, hit_rate_result, ndcg_result], axis=1), index=["MRR", "Hit Rate", "nDCG"])
return results_df
What’s happening? This function evaluates a retriever by computing three metrics (MRR, Hit Rate, nDCG) for each query in the dataset and returns the average scores in a DataFrame.
1️⃣4️⃣ Displaying Results
def display_results(name, eval_results):
metrics = ["MRR", "Hit Rate", "nDCG"]
columns = {"Retrievers": [name], **{metric: val for metric, val in zip(metrics, eval_results.values)}}
return pd.DataFrame(columns)
pd.concat([
display_results("Embedding Retriever", embedding_retriever_results),
display_results("BM25 Retriever", bm25_results),
display_results("Embedding + BM25 Retriever + Reranker", embedding_bm25_rerank_results),
], ignore_index=True)
Why this? This code displays the evaluation results for non-contextual retrievers in a neat table, comparing their performance across MRR, Hit Rate, and nDCG metrics.
1️⃣5️⃣ Contextual Retriever Results
pd.concat([
display_results("Contextual Embedding Retriever", contextual_embedding_retriever_results),
display_results("Contextual BM25 Retriever", contextual_bm25_results),
display_results("Contextual Embedding + BM25 Retriever + Reranker", contextual_embedding_bm25_rerank_results),
], ignore_index=True)
What’s this? Similar to the previous step, this displays results for contextual retrievers, allowing us to compare their performance against non-contextual ones.
🎉 Wrapping Up
Congratulations! You’ve just explored how to implement Contextual Retrieval using LangChain. By adding context to chunks, combining retrievers, and evaluating performance, you’ve built a smarter search system. Try tweaking the code and experimenting with your own datasets to see how it performs! 🌈
Comments
Post a Comment